SURF, het CREATE lab en de Amsterdam Time Machine hebben het afgelopen half jaar gewerkt aan Meaningful Memories: een prototype van een pipeline om oral history bronnen met een open audiotranscriptiemodel en large language model (LLM) te transcriberen en te annoteren. Tijdens de Datasprint op 18 juni werd de pipeline uitgeprobeerd.
Amsterdam Diaries: automatisch en inclusiever
De directe aanleiding om dit prototype te ontwikkelen was het Amsterdam Diaries Time Machine-project. De dagboeken voor deze website transcibeerden en annoteerden we grotendeels met de hand. Hoe mooi zou het zijn om een deel van het (voor)werk ook automatisch uit te kunnen voeren?
Daarnaast richtten we ons met de eerste versie van de Diaries sterk op één soort bronnen: geschreven dagboeken van Amsterdamse vrouwen in de Tweede Wereldoorlog. Natuurlijk willen we de focus van de Diaries verbreden en inclusiever maken, door ook gesproken bronnen en geschiedenissen (zoals oral history interviews) op te nemen, doorzoekbaar te maken en als Linked Open Data te verbinden met ander erfgoedmateriaal. Een groot deel van de Amsterdammers kent een traditie van mondelinge overlevering van familieverhalen, die onlosmakelijk onderdeel van de geschiedenis van de stad uitmaken.
Het probleem met oral history interviews is dat ze doorgaans (nog) niet op fragment doorzoekbaar zijn. Door de inzet van LLMs zouden we dat wellicht wel voor elkaar kunnen krijgen, waardoor de interviews en audiovisueel bronnenmateriaal in het algemeen veel beter toegankelijk en doorzoekbaar worden. Met Meaningful Memories hebben we hiervoor de eerste stap gezet.
 SURF was geïntereseseerd in deze pilot vanwege het mogelijke nut voor alle onderzoekers die in hun onderzoek gebruik maken van interviews of gesproken narratieven: in de geesteswetenschappen, maar ook in andere domeinen zoals psychologie of gezondheidszorg. De pilot sluit aan bij lopende projecten als HOSAN (Hoogwaardige Spraakherkenning voor het Nederlands) en GPT-NL, maar kan ook nuttig zijn voor toekomstige (Nederlandse) spraakprojecten.
SURF was geïntereseseerd in deze pilot vanwege het mogelijke nut voor alle onderzoekers die in hun onderzoek gebruik maken van interviews of gesproken narratieven: in de geesteswetenschappen, maar ook in andere domeinen zoals psychologie of gezondheidszorg. De pilot sluit aan bij lopende projecten als HOSAN (Hoogwaardige Spraakherkenning voor het Nederlands) en GPT-NL, maar kan ook nuttig zijn voor toekomstige (Nederlandse) spraakprojecten.
Doel van het project
Het project had als doel een modulaire pipeline te ontwikkelen met het gebruik van open, vooraf getrainde Large Language Modellen (LLMs) om audio te transcriberen, namen en concepten uit de transcriptie te extraheren en deze informatie te verbinden met externe Knowledge Graphs, zoals AdamLink en Wikidata.
Samenwerking met Amsterdam Museum en de Master Publieksgeschiedenis van de UvA
In het kader van de 750ste verjaardag van Amsterdam gebruikten we twee speciale databronnen uit de collectie van het Amsterdam Museum. Deze bronnen zijn in de afgelopen tien jaar verzameld en geproduceerd door studenten van de Master Publieksgeschiedenis van de Universiteit van Amsterdam. We werkten met uitgeschreven interviews waarin de studenten Amsterdammers vroegen naar hun favoriete plek in de stad en met audio-interviews waarin Amsterdammers met persoonlijke verhalen een bijdrage leverden aan de biografie van Amsterdam.
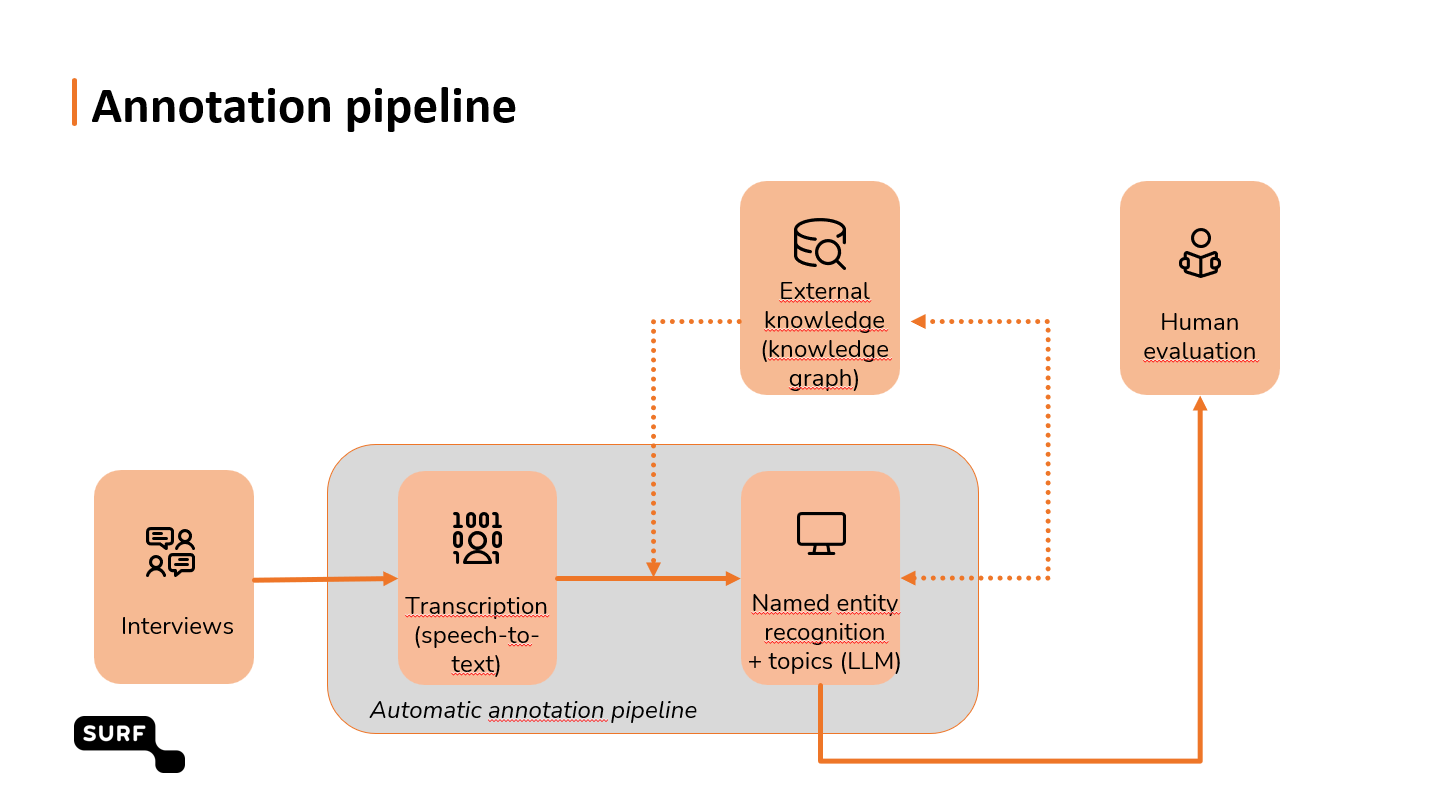
De doorlopen stappen
We hebben een aantal stappen doorlopen om de pipeline werkend te krijgen. Dit gebeurde met lokale modellen in de SURF AI-hub, on-site of via de laptop, gebruik makend van de computerkracht van Snellius.
 De eerste stap (op woordniveau) was het omzetten van spraak naar tekst (met Whisper en WhisperX). De tweede stap (op zinsniveau) bestond uit het geautomatiseerd markeren van namen van personen, locaties en organisaties (Named Entity Recognition (NER) met GLiNER). De derde stap (op paragraafniveau) was het automatisch identificeren van thema’s met Large Language Model Llama3. We hebben de LLM “vrij” laten genereren en vervolgens gekozen voor thema’s die pasten bij een specifiek interview. Zo kwamen we bijvoorbeeld op de thema’s: vrijheid, studenten, muziek, cultuur en identiteit.
De eerste stap (op woordniveau) was het omzetten van spraak naar tekst (met Whisper en WhisperX). De tweede stap (op zinsniveau) bestond uit het geautomatiseerd markeren van namen van personen, locaties en organisaties (Named Entity Recognition (NER) met GLiNER). De derde stap (op paragraafniveau) was het automatisch identificeren van thema’s met Large Language Model Llama3. We hebben de LLM “vrij” laten genereren en vervolgens gekozen voor thema’s die pasten bij een specifiek interview. Zo kwamen we bijvoorbeeld op de thema’s: vrijheid, studenten, muziek, cultuur en identiteit.
Tenslotte is alle informatie verbonden met externe bronnen zoals Wikidata, AdamLink, het Termennetwerk van NDE, de Cultureel Erfgoedthesaurus van RCE en de GTAA (Gemeenschappelijke Thesaurus voor Audiovisuele Archieven).
Het schema
In schematische weergave ziet dat er zo uit:
Mensenwerk is nodig!
Uiteraard maken computers en AI fouten. Daarom hebben we de recente datasprint van de Time Machine (18 juni 2025) gebruikt om de output van de pipeline te testen. Een groep van zo’n 15 onderzoekers, erfgoeddeskundigen en Amsterdammers met interesse in data ging aan het werk om de annotaties te controleren, te corrigeren en waar mogelijk en wenselijk aan te vullen. Dat deden ze in LabelStudio in een speciaal voor de datasprint opgezette webomgeving. De aanvullingen en verrijkingen werden uiteindelijk opgeslagen in een eerste proefversie van een AnnotatieRepository (van NDE en KNAW-HuC) in de Web Annotation standaard, zodat ze later hergebruikt kunnen worden en/of kunnen worden teruggeleverd aan het Museum als toevoeging aan de catalogus.
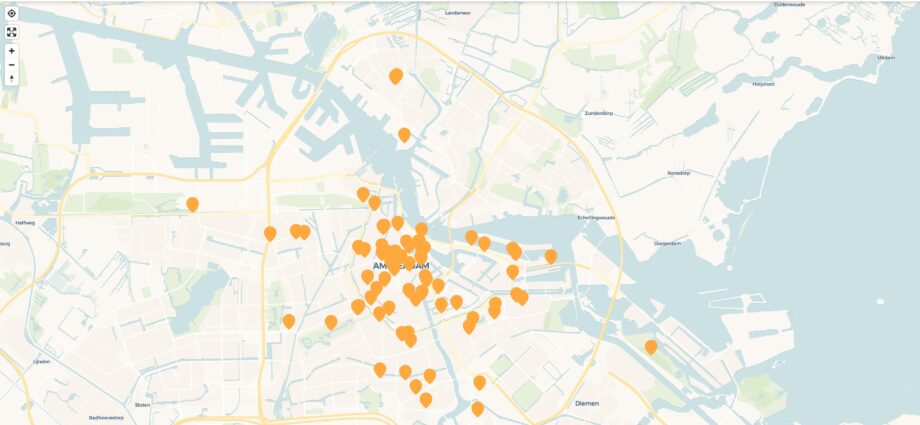
Eén middag datasprinten liet zien dat de pipeline inderdaad werkt. Een groepje van zo’n 15 mensen heeft in een paar uur bijna 2000 annotaties kunnen controleren, verbeteren en visualiseren. Het eindresultaat konden we aan het einde van de dag tonen op de kaart van Amsterdam.
Het resultaat
In het pilotproject hebben we zoveel mogelijk bestaande technologie gebruikt en er een toegevoegde waarde aan meegegeven in de vorm van een geautomatiseerde end-to-end oplossing. Voor dit project maakten we uiteraard een specifieke keuze wat betreft de entiteiten, de gelinkte externe bronnen en het LLM (grootte o.b.v. de infrastructuur).
De pipeline is modulair van opzet, zodat de elementen te hergebruiken zijn. De kwaliteit van de output is een punt van aandacht. Ook merkten we dat context belangrijk is voor goede werking van LLMs. Korte zinnetjes zijn moeilijker te interpreteren en leiden tot veel fouten.
En nu?
Het project heeft een werkende proof of concept opgeleverd en we kijken er naar uit de samenwerking voort te zetten en het prototype door te ontwikkelen tot een volwaardige tool. Dit bij voorkeur als onderdeel van een bredere onderzoeksinfrastructuur, zodat meer onderzoekers er gebruik van kunnen gaan maken. Additionele financiering is dan wel een voorwaarde.
Natuurlijk is de output die we tijdens de Datasprint hebben gecureerd maar een fractie van alle informatie die via de pipeline uit de twee bronnen van het Amsterdam Museum/Publieksgeschiedenis UvA toegankelijk is gemaakt. In november van dit jaar komt er een nieuwe datasprint. Wil je zelf ook eens aan de slag met dit materiaal? Houd de agenda van de Time Machine dan in de gaten en meld je t.z.t. aan.
Dank!
Het projectteam bestond uit: Simone van Bruggen en Annette Langedijk van SURF, Leon van Wissen, Boudewijn Koopmans en Ingeborg Verheul van de Amsterdam Time Machine/UvA CREATE Lab.
Met speciale dank aan Nikki Pouw en Judith van Gent van het Amsterdam Museum, aan Laura van Hasselt en Paul Knevel van de Master Publieksgeschiedenis van de UvA en aan de curatoren van de datasprint.
Handige links:
- Beschikbare Code op GitHub SURF
- GitHub ATM Datasprint op 18 juni 2025 (zie ook de blog elders op deze website)
- Presentatie Simone van Bruggen (Datasprint)
- Presentatie Laura van Hasselt en Paul Knevel (Datasprint)
- Abstract DH Benelux
- Poster MM DH Benelux Simone van Bruggen
- 25_DARIAH_abstract_panel_OH Annette Langedijk
- 25DARIAH_OralHistoryPanel_slides_AnnetteLangedijk